Visualizing how fractions are written as decimal digits
Posted by jimblackler on Jul 5, 2015
For a demo click here
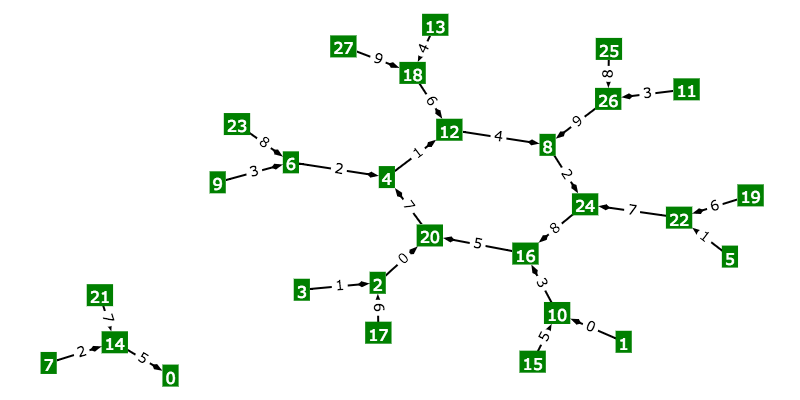
I’ve written a web app that generates diagrams showing the sequence of digits when a fraction (such as ¼) is written in decimal form (0.25). One diagram can be used for every fraction (non-negative proper fraction) with a particular value on the bottom (the denominator). My program feeds data into the springy.js framework which uses a force-based layout to draws network diagrams of graphs.
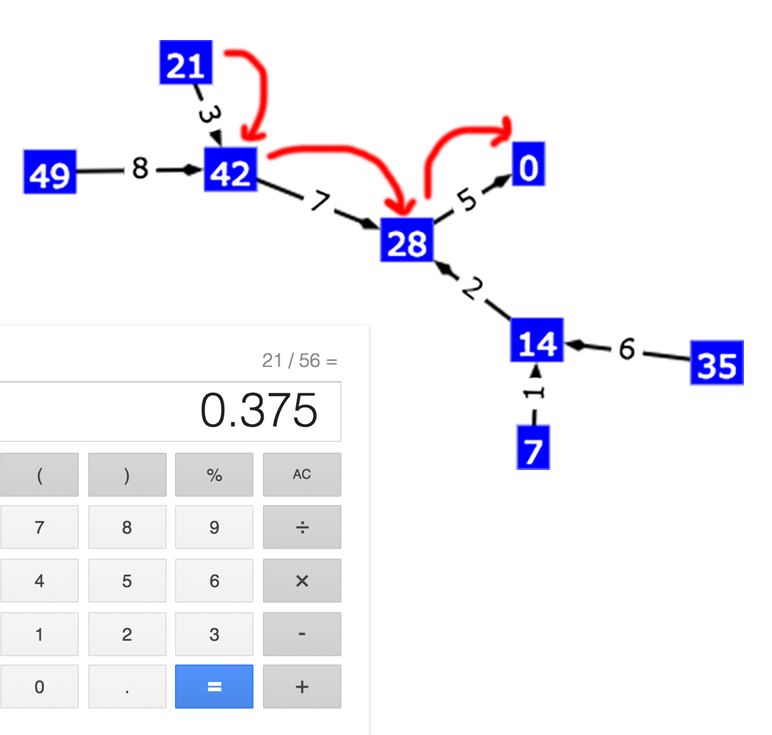
To see how to find the decimal form of 21 / 56, click on the demo link. This diagram can be used to find the decimal form any non-negative proper fraction with 56 on the bottom.
Start by writing down “0.” (since all simple fractions are no less than zero but under one). Then find the vertex labeled ‘21’, your numerator (the top part of the fraction). Next simply follow the arrows, writing down the numbers on the arrows as you go. The arrow labeled “3” takes you to vertex 42 (write down “3”), “7” to vertex 28 (write down “7”), and “5” to vertex 0 (write down “5”). We always stop at ‘0’ so the sequence is complete.
You’ve written “0.”, “3”, “7”, “5”. A quick check on a calculator will confirm that 21 / 56 is equal to 0.375.
This diagram works for all other fractions with a denominator of 56 and numerator between zero and 55. On the same diagram try for ‘18’. The sequence starts out “3”, “2” but after a bit you’ll find you’re in a cycle that starts “1”, “4”, “2”, “8”, “5”, “7”, then returns to “1”.
Checking with a calculator shows me that 18 / 56 is 0.32142857142857142857… repeating forever.
Motivation
I made the app because I was wondering if there was a rule to say which fractions had repeating sequences when written as decimals, and it occurred to me how easy it would be to generate a graph from the data using a standard tool. I’m still thinking about the rule problem, but the diagrams help visualize the problem.
More diagrams
Here are some more examples for fractions of different denominator values.
Note that you can change the values in the input boxes then hit return. You can also use the up/down arrow boxes when an input box is enabled.
Springy is like most popular graph diagram generators in that it uses a spring system to arrange the vertices.
This makes it interesting and fun to.manipulate. However you usually need to ‘unknot’ diagrams by hand to remove any overlapping edges. A graph drawing algorithm could be tailored to generate these diagrams while maintaining more of the symmetry and making overlapping edges impossible.
How it works
Pseudocode to generate the diagram:
for (numerator = 0; numerator != denominator; n++) {
// make a vertex labeled ‘numerator’
}
for (numerator = 0; numerator != denominator; n++) {
digit = (numerator * 10) / denominator;
next = (numerator * 10) % denominator;
// make an edge from ‘numerator’ vertex to ‘next’
// vertex, labeled ‘digit’
}
To understand how this works, consider how you might find just the first digit after the decimal point in an expansion of a fraction n / d (non-negative proper fraction). Remember that in general, multiplying a number by 10 shifts its decimal point one position to the right. If we do that to any fraction we get 10n / d. Now what was the first digit of its decimal form (right of the decimal point) is now to the left of the decimal point. So the whole part (the ‘quotient’) of 10n divided by d will give us the first decimal digit. The remainder of 10n divided by d (still over d) represents the part to the right of the decimal point, which is the rest of the decimal string (discarding the leading ‘0.’). Since ‘n’ hasn’t changed we can find this value on the same diagram, and repeat the process to get the next digit, then continue forever to get the whole string!
Let’s look at an example 25/27. Your calculator will show you this is 0.9259259259259259. But let’s verify with this method.
25 multiplied by 10 is 250, which divided by 27 is equal to 9 + 7 / 27. “9” is the whole part (the quotient) and this is the first digit. 7 / 27 is the remainder which is the rest of the string. Indeed, my calculator tells me this is 0.25925925925925924. If I repeat the process for 7 / 27, I get 70 / 27 which is 2 + 16 / 27. “2” is the next digit. Repeat with the remainder, so 16 / 27 goes to 160 / 27 which is 5 + 25 / 27. The next digit is “5”, but now our remainder is what we started with. So we will repeat “9”, “2”, “5”, forever, verifying the calculator result of 0.925925925….
Different bases
What if we wanted to see how fractions would be written in systems other than decimal, such as binary or hexadecimal? Changing the base is as easy as changing the number 10 in our calculations above. This diagram shows part of a binary base expansion.
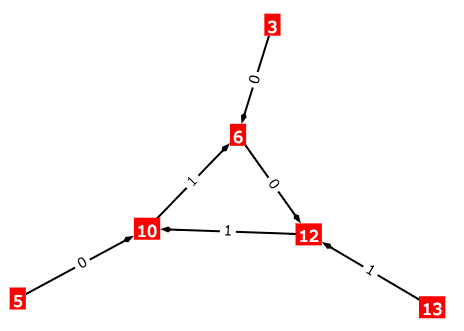
Some more examples:
Patterns
We get lots of interesting patterns from playing with the numbers, but whatever you do, certain constraints arise. Many of thse are from the fact that the kind of graph we create is a directed pseudoforest, that is, every vertex has exactly one edge out (although this may be to itself).
Given the ‘many to one’ relationship between the different vertices (each vertex has just one edge out) you can only ever end up with one or more subgraphs of connected vertices formed of a ‘hub’ (one or more vertices in a cycle) and ‘spokes’ (non cycling or tree graphs heading into the hub).
The rough explanation is that a walk starting at any vertex you will always end in a cycle or (closed walk) since even ‘0’ has an edge back to itself. Any other vertex with a walk reaches any vertex on this cycle will be part of the same subgraph (connectable in any direction on the edges). Since any walk can only have one cycle, no other cycles can exist in this subtree. So, all walks entering the cycle can be drawn as trees rooted at the position they enter the cycle.
But beyond that in this specific case (the fraction graphs) you see some really interesting patterns just by changing the numbers.
Note how values of ‘d’ that have no factors in common with the base (in the case of 10 can’t be evenly divided by 2, 5 or 10) have subgraphs that are all cycles.
You might consider how d’s prime factors (including if they are in common with the base’s prime factors or not) affect the shape of the graph. You might ask what determines the number of subgraphs, or the number of vertices in the cycles, and whether they are all the same.
Another interesting thing about this is the whole graph is a closed walk (starting at any value will end up in the original position) you now have a graph equivalent to the kind encountered in the modular arithmetic used in cryptography.
Source
I hope you enjoy the app. The source can be found on GitHub.
Accessing the internal calendar database inside Google Android applications
Posted by jimblackler on Oct 23, 2009
The Android phone operating system provides close integration with three excellent services from Google; email, address book and calendar. In addition it has a thriving third party app scene with a great variety of free and commercial applications on the Market. In theory this should mean that apps can provide new services to the user based on the Google service data they have already synced on the phone.
However in the case of calendar data this has proven a bit tricky. Google provide an API to access calendar data via the internet, and this can be used directly from Android apps. Unfortunately this also requires a working data connection, time and battery life to get at the data. In addition it will need the app to prompt for the user’s credentials (user name and password).
All this seems unnecessary when the data you want is right there on the phone already. Since there is an API that any application can use to access the user’s contact (address book) data directly on the phone without going to the internet. It’s called android.provider.Contacts and is documented here. So why doesn’t android.provider.Calender exist?
The answer
The answer is that is does exist – although it is not documented, and it is not included with the standard Google Android SDK. It is a little-known fact that it is possible to download the Android source, force the provider classes to be included by removing the @hide annotation that protects it, and make your own version of the SDK. This can be compiled against apps from which calendar queries can then be made.
This is how I originally built my app Quick Calendar – a ‘lite’ read only version alternative to the built-in calendar application released early 2009. This uses the same data used by the built-in calendar application, already synced onto users’ Android phones. Judging by my inbox it’s been the most popular hobby application I’ve ever put out. I’ve since had a number of inquires from other developers as to how I managed get at the internal calendar data on Android.
Firstly I would say that getting at the data by a custom-build SDK is possible but awkward. For one thing it is a pain keeping up to date with the latest changes and staying in sync with the Android Eclipse plug in.
The good news is you don’t actually need to use the calendar provider SDK classes to get at the data. Android exposes data across applications by using a feed system similar to web-based feeds, and query syntax similar to SQL. As a result, provided your app has the correct user permission (android.permission.READ_CALENDAR) you can query the database from the names, and continue to use standard SDKs such as 1.5 or 1.6. In the absence of specific SDK support for calendars, it’s only slightly less convenient to directly use the provider’s internal URIs (e.g. “content://calendar/calendars”) directly.
Warning
At this point I should point out that there’s a reason why Google haven’t officially exposed the internal calendar APIs. This is probably because they anticipate future changes to the calendar format. Once they’ve published an SDK the formats are to some extent set in stone and they’d like to avoid that. In my experience the formats have been stable since I first discovered the feed. However, don’t be surprised if future firmware changes break any apps that use the feed. In this event you’ll have to update your app and re-upload it to the Market. It’s not that big a worry, certainly not enough to avoid using this great feature – the ability to present users’ calendar data in new ways to them.
Example
I’ve uploaded an example project to http://svn.jimblackler.com/jimblackler/trunk/workspace/AndroidReadCalendarExample. All the calendar reading code is in http://svn.jimblackler.com/jimblackler/trunk/workspace/AndroidReadCalendarExample/src/net/jimblackler/readcalendar/Example.java.
To read the calendar data in your own app firstly add android.permission.READ_CALENDAR under <manifest> in your application’s AndroidManifest.xml.
Please note that you will probably have to use a real phone to test your app in development, because the emulator included with the SDK does not include the Google services (there will simply be no calendar database present to query).
Then get an android.content.ContentResolver and make a query to content://calendar/calendars to enumerate all the available calendars
on the phone. The ‘_id’ column will give you the calendar’s ID (referenced in events). You can get rough documentation of all the columns supported by looking at core/java/android/provider/Calendar.java. (As mentioned previously, this file is part of the public open source Android project but is not part of the official Android SDK from Google)
- ContentResolver contentResolver = context.getContentResolver();
- final Cursor cursor = contentResolver.query(Uri.parse("content://calendar/calendars"),
- (new String[] { "_id", "displayName", "selected" }), null, null, null);
- while (cursor.moveToNext()) {
- final String _id = cursor.getString(0);
- final String displayName = cursor.getString(1);
- final Boolean selected = !cursor.getString(2).equals("0");
- System.out.println("Id: " + _id + " Display Name: " + displayName + " Selected: " + selected);
- }
Once you have a calendar ID you can use your ContentResolver object to obtain the events from that calendar. Note how a ‘where’ clause of ‘Calendars._id=??’ is employed to fetch only events of that particular calendar. This clause could query whichever columns your app required, using an SQL-like syntax. Note also how the Uri.Builder was used to build up a URL including date bounds for the query.
- Uri.Builder builder = Uri.parse("content://calendar/instances/when").buildUpon();
- long now = new Date().getTime();
- ContentUris.appendId(builder, now - DateUtils.WEEK_IN_MILLIS);
- ContentUris.appendId(builder, now + DateUtils.WEEK_IN_MILLIS);
- Cursor eventCursor = contentResolver.query(builder.build(),
- new String[] { "title", "begin", "end", "allDay"}, "Calendars._id=" + id,
- null, "startDay ASC, startMinute ASC");
- while (eventCursor.moveToNext()) {
- final String title = eventCursor.getString(0);
- final Date begin = new Date(eventCursor.getLong(1));
- final Date end = new Date(eventCursor.getLong(2));
- final Boolean allDay = !eventCursor.getString(3).equals("0");
- System.out.println("Title: " + title + " Begin: " + begin + " End: " + end +
- " All Day: " + allDay);
- }
Note that all dates in the calendar format are stored as UTC (the number of milliseconds that have elapsed between midnight 1st January 1970 and the event in Greenwich UK).
This is the basics of calendar access on Android. I haven’t covered all the columns (these can be seen in the SDK source linked above) and I haven’t covered modification. Notheless I hope this information allows other developers to build great calendar-aware apps for Android. Please do leave queries in the comments here, and if you use this information to make an app please do tell us about it in the comments here.
Update
To access the Corporate Calendar on Motorola devices, use “content://calendarEx” in place of “content://calendar”.
Update 2
For Android devices using 2.2 (Froyo) or greater, where previously you had content://calendar you should write content://com.android.calendar
Viewing raw XML traffic when using Google Data Java Client APIs
Posted by jimblackler on Oct 23, 2008
The Google Data Java Client APIs provide a convenient way for Java prorgams to interface with Google’s public Data APIs, for Google calendars, contacts, and many other services.
It’s such a good abstraction, however, there is no clear way of seeing the underlying XML of the feed. When debugging, and for their interest, programmers may wish to see this data – it’s supposed to be human-readable after all.
After at least an hour of playing around I found the commands to enable the logging in the client’s initialization. Traffic will then be output to the console at run time.
The gotcha is that enabling verbose output on Java’s logging requires not just the logs to be set to Level.ALL, but also the underlying handlers.
Here’s the code.
- import java.util.logging.Logger;
- import com.google.gdata.client.http.GoogleGDataRequest;
- import com.google.gdata.client.http.HttpGDataRequest;
- Logger.getLogger(Logger.GLOBAL_LOGGER_NAME).getParent().getHandlers()[0].setLevel(Level.ALL);
- Logger.getLogger(GoogleGDataRequest.class.getName()).setLevel(Level.ALL);
- Logger.getLogger(HttpGDataRequest.class.getName()).setLevel(Level.ALL);
Bringing ‘yield return’ from C# to Java
Posted by jimblackler on Oct 12, 2008
Consider a function that collects and returns a list of results. It might look like this:
- public ArrayList<String> retrieveAll(long requesterId);
Or even better, this, so it could use anything that implements Iterable<>:
- public Iterable<String> retrieveAll(long requesterId);
However, storing the results in a container which is then returned may be inefficient for the application. It may be better to enable the calling code to act immediately on each collected result rather than first waiting for all results to be collected and stored. If that were possible..
- No memory would be used to store a list.
- Results could be presented to the user straight away.
- Calling code could abort the collecting process part way through based on its own logic – for instance if it already has more results than it can handle.
Custom iterators
One way to avoid an intermediate list is for the collecting function to construct a custom Iterable<> object, which constructs Iterator<> objects that contain the collecting logic. Each execution of next() calculates the next value and returns it straight away for the calling code.
The difficulty for the programmer is that this may require a significantly different structure of the collecting code. This code has to store any state from result to result as private variables inside the iterator. Call stack is reset with each result, so algorithms that use recursion are not possible.
More convenient for the programmer would be a technique that allows the collecting code to keep control of the machine state during the collecting process.
Yield return
C# has ‘yield return’ which allows a function to be structured exactly as if it is building a list. It may keep its own state in local variables and the call stack, but still present each value to the calling code immediately as it is found.
Java doesn’t have yield return, but another pattern that could be used is this:
- public void retrieveAll(long requesterId, ResultProcessor<String> collector);
Where ResultHandler<> is a simple interface to an object invoked by the collecting code to return individual results as they are collected.
- public interface ResultHandler<T> {
- void handleResult(T value) throws CollectionAbortedException;
- }
It is left up to the calling code what ResultHandler<> implementing object to supply, and how to handle the data. Anonymous classes would be quite neat here. For instance, a caller could output the results to a console like so:
- retreiveAll(myId, new ResultHandler<String>(){
- public void handleResult(String value) {
- System.out.println(value);
- }
- });
The collect() function may abort the collecting operation part way through by throwing a CollectionAbortedException.
The disadvantage to this approach is that it is a little less convenient from the perspective of the calling code. The function has a novel pattern, taking ResultHandler<> as a parameter rather than the more familiar Iterable<> as a return value. Logic has to be embedded inside an anonymous or specially constructed ResultHandler<> class.
Unlike the case of returned Iterables, the calling code can not use ‘for each’ loops on the result. Nor can it store or pass around the Iterable<> to other systems as a parameter.
Solution : The yield adapter
A best-of-both-worlds solution would allow a collecting method based on ResultHandler<> to be automatically adapted at run time to an implementation based on Iterable<>. A data-collecting function implemented in this form (convenient for the collecting code) …
- public void retrieveAll(long requesterId, ResultHandler<String> collector);
.. would be adapted into this form (convenient for the calling code)..
- public Iterable<String> retrieveAll(long requesterId);
This would provide the same benefit C# programs get from yield return. Namely, the ability for both collecting code and calling code to have their own machine state and callstack control throughout the entire collecting and processing operation. It is not necessary for either side to separate logic into methods inside anonymous classes. Collecting code can use complex recursion algorithms. Calling code can store and defer use of the Iterable<> used to collect results, or pass them as parameters to other functions.
| Approach | Collector controls flow | Caller controls flow | Requires list | Caller can abort collect | Uses new thread |
| Collector builds and returns list in form of Iterable<> | yes | yes | yes | no | no |
|
Collector returns Iterable<> containing logic |
no | yes | no | yes | no |
| Caller passes in ResultHandler<> | yes | no | no | yes | no |
| ResultHandler<> wrapped to Iterable<> with yield adapter. | yes | yes | no | yes | yes |
How it works
I am not the first engineer to attempt to bring yield to Java. Aviad Ben Dov’s article in 2007 http://chaoticjava.com/posts/java-yield-return-code-published/ describes a way to do this using bytecode manipulation and classloader modification. My view is that a solution in Java alone would be more practical as a portable library.
My starting premise was that if calling code and collecting code are both to have their own call stack, this could only be achieved with the use of multiple threads.
In addition, I was aware of a Java collection SynchronousQueue which is designed to allow two threads to pass values between each other, each in turn yielding control to the other.
The Yield Adapter simply makes a new custom Iterable<> which is returned to the calling code. The iterable creates iterators on demand, which also starts a new thread for the collection, and makes a SynchronousQueue for communication between the two. Results are wrapped in message object and, .put() into the queue on the collecting side. The iterator side uses .take(). There is also some extra logic to ensure that incomplete reads do not result in leaked resources.
Please note that although the adapter uses threads, the code does not normally need to be ‘thread safe’ in the classic sense. That is because there is never a time that both threads are executing simultaneously. One thread always ‘yields’ to the other. The exception to this is if multiple iterators were ever in effect at once.
Source and demos
The adapter source can be found here with the interfaces employed all here.
A demo here shows how the adapter can be used to allow a recursive scan of files and directories, returning the result through an iterator.
A more complex demo here returns all possible ways the letters in a word can be rearranged, without repeats.
The library source can be downloaded with Subversion or your browser here and the tests and demos are here.
Feedback
I hope that this small library will allow people to develop complex algorithms that present results to calling code as iterators.
If you have any comments on the code, please add them as comments on this article.
Update Feb 2009
Many thanks to Dominic Lachowicz who brought to my attention the fact that the SynchronousQueue does not in fact stop both threads running at the same time. A revision checked in today uses a Semaphore object to achieve the desired behaviour.
Selecting a number of random elements from a list, without repeats. An implementation in Java.
Posted by jimblackler on Apr 13, 2008
A project I’ve been working on required a random selection of postings to be shown to users. The entries were to be drawn from a larger list : a cache of references to posts held in memory.
My first effort at the selection code simply copied the original list, shuffled it, then selected the first ‘n’ entries (where ‘n’ is the number of required postings). A colleague remarked that this was hardly an optimal use of time or memory. So I decided to write a a general-purpose function to select ‘n’ unique entries from a list of ‘m’ entries – using as little memory and processing time as possible.
A naive solution
The most obvious solution to the problem is to repeatedly draw random entries from 0.. n of the list. To reduce the repeats, keep a record of the indices of the random entries already selected. Then, as each new item is selected, the existing list is checked to see if the entry was already taken.
The problem with this is that as more entries are selected the likelihood of such a collision increases. The execution time of the function cannot therefore be predicted. In some cases where the number to select was very large this could make the function quite slow. You could speed it by using different containers and such, but a better approach seems to be avoid collisions in the first place.
Consider a case of selecting five random entries from a list of ten. The first entry index can be found by picking a random number between zero and nine. When making the second selection however there are now only nine remaining unselected entries. So if we pick from zero to eight, then find a way of converting this number (the index of unused entries) into a full source table index, we have avoided the possibility of collision altogether.
The method
My solution calls for items chosen using a random number generated between 0 and m-c where ‘c’ is the number of already selected items. This represents the relative index of unchosen entries, not the actual entries themselves. This number is then converted into the actual entry index by an algorithm.
This algorithm involves iterating backwards through the list of already picked random numbers. The principal is at each iteration to convert the index from 0… m-c space to 0 .. 1+m-c space. In other words the space of the previously selected element. One single operation can do this, and at the same time avoid any potential collision with the last drawn entry in its target space. The operation says “if the already selected entry’s unchosen entry index is the same or less than the current index number then increment this index by one.”
When all already selected entries have been processed in this way, the resulting index is guaranteed to be in 0.. n space and clear of any collisions with already selected entries.
The method has an order of execution n*m / 2, and temporary storage requirements of n indices. This is stable and predictable however so it is a in improvement on collision avoidance methods that would mean repeating random selections.
Code
Here is a ready-to-use implementation in Java.
- import java.util.List;
- import java.util.Random;
- import java.util.ArrayList;
- public class ListUtil {
- /**
- * Create a new list which contains the specified number of elements from the source list, in a
- * random order but without repetitions.
- *
- * @param sourceList the list from which to extract the elements.
- * @param itemsToSelect the number of items to select
- * @param random the random number generator to use
- * @return a new list containg the randomly selected elements
- */
- public static <T> List<T> chooseRandomly(List<T> sourceList, int itemsToSelect, Random random) {
- int sourceSize = sourceList.size();
- // Generate an array representing the element to select from 0... number of available
- // elements after previous elements have been selected.
- int[] selections = new int[itemsToSelect];
- // Simultaneously use the select indices table to generate the new result array
- ArrayList<T> resultArray = new ArrayList<T>();
- for (int count = 0; count < itemsToSelect; count++) {
- // An element from the elements *not yet chosen* is selected
- int selection = random.nextInt(sourceSize - count);
- selections[count] = selection;
- // Store original selection in the original range 0.. number of available elements
- // This selection is converted into actual array space by iterating through the elements
- // already chosen.
- for (int scanIdx = count - 1; scanIdx >= 0; scanIdx--) {
- if (selection >= selections[scanIdx]) {
- selection++;
- }
- }
- // When the first selected element record is reached all selections are in the range
- // 0.. number of available elements, and free of collisions with previous entries.
- // Write the actual array entry to the results
- resultArray.add(sourceList.get(selection));
- }
- return resultArray;
- }
Running Java applications on OSX (Mac), that were developed with NetBeans on Windows
Posted by jimblackler on Jan 1, 2008
Mac and Java 1.6 (or the lack thereof)
Java SE provides a great opportunity to create applications that will run on Windows, Linux and Mac from the same single .jar executable file. All the end user needs is Java installed, and this is installed as standard for many OSes.
Unfortunately at the time of writing, Jan 2008, there is a problem with targeting Macs. Even the latest version of the Mac operating system OSX 10.5 (Leapard) does not include the latest version of Java, 1.6, that has been the default in Windows-based Java IDEs for a year at least.
A beta can be downloaded but this requires registration on the developer sites, cannot run on OSX 1.4 (Tiger), requires an Intel 64 bit processor, and has other restrictions. Right now it’s far from ideal for a mainstream application, and it’s hard to imagine that even when released officially 1.6 will reach a critical mass of deployment until 2009 at least.
The Windows NetBeans to Mac problem
Unfortunately GUI applications developed with the latest Windows NetBeans 5.5 (the free Java API from Sun) require some configuration to allow applications to be developed that run on out-of-the-box Macs. This is not just because of the OSX Java 1.6 problem, but also some glitches with the “backport” targeting in NetBeans. This affects GUI applications developed with NetBeans GUI editor which uses Swing, a cross-platform GUI layer for Java.
It is not enough to set the source level to 1.5 in the project properties, but to continue to use the 1.6 JDK. This will not run on OSX with 1.5 JRE. The error in the Console will be:
java.lang.NoClassDefFoundError: javax/swing/GroupLayout$Group
The problem is that when using NetBeans’ Swing editor with the 1.6 JDK will create code that won’t run on machines that have Java 1.5. This is because it inserts references to javax.swing.GroupLayout, which only exists in 1.6 onwards. Misleadingly, it does this even if ‘source level’ is set to 1.5.
The solution
This can be fixed by downloading the 1.5 JDK (aka the Java Development Kit 5.0 Update 14) and set your NetBeans project to use it. When new Swing GUI elements are created with this JDK set, the IDE uses the org.jdesktop.layout.GroupLayout class instead. This is not built into the JRE but the additional files can be bundled in your .jar. More about this in a second.
The file you require is jdk-1_5_0_14-windows-i586-p.exe and can be downloaded from Sun. Once installed, in NetBeans select Tools->Java Platform Manager. Click Add Platform and choose C:\Program Files\Java\jdk1.5.0_14.
In your applications, in the properties panel, select Libraries, then set the Java Platform to Java Hotspot(TM) Client VM 1.5.0 14-b03 which should now be available. It is important that you do this before you add any Frames as the act of doing this generates the code that must use the correct version of GroupLayout.
The last step is to ensure that the files that 1.5 users (i.e. Mac users) will require are bundled into your .jar, follow the instructions here.
In conclusion
Following these instructions will results in a .jar file that can run on any out-of-the-box installation of OSX, Windows (with latest Java), or Linux.
A great benefit of cross-platform Java SE with Swing is that you can create applications that use all the standard “native” GUI controls for the platforms on which they run. The end-user will have little idea that Java was used, they’ll just see it as an application that looks like it was developed for their choice of OS. To make your Swing applications use native look and feel, follow the instructions under “Programatically Setting the Look and Feel” here
Standard whitespace, Visual Studio style
Posted by jimblackler on Oct 15, 2007
Stressing about standard code appearance in a large team project is fairly low on my list of priorities, but it is on the list.
I’m happy to change my style to fit in, but as every project has a different ‘standard’, it’s annoying to have to keep changing.
“The wonderful thing about standards is that there are so many of them to choose from.” Grace Hopper
Visual Studio has, from VS 2002, offered a facility to ‘format’ some code files. This format actually means convert the whitespace to a standard form. This form is apparently of Microsoft’s own design.
I was delighted to see this feature, however, as it meant that there was an easy way that a common format for whitespace could be set in a large team. Yes there are formatting utilities out there, and VS is just one of the many IDEs available. VS is however a very popular IDE in the world of commercial development.
The actual keypresses and modes vary by language, VS version, and configuration. In some modes it is automatic, in others you can press CTRL-E-D. You can format C++, C#, Visual Basic or XML. The .NET languages have controllable options and seem to format more effectively.
Over the last couple of years I’ve got so familiar with the VS format that I apply the style manually when working with non-VS languages like Javascript, Actionscript and PHP.
I have reversed engineered the default VS style so that you can do the same if you like! These are the basics. The general rule is that all tabs and spaces are stripped with the exception of:
Indentation
Braces appear on a line of their own (controversial!) at the same indentation level as the parent. Block content appears indented.
- class MyClass
- {
- int Method()
- {
- return 3;
- }
- }
Case labels and content are each indented.
- switch (name)
- {
- case "John":
- break;
- }
Comments appear in the first column without indentation.
Indentation is not changed for the second and further lines for any instruction that spills over multiple lines. The default however is that it is indented from the first line.
- {
- bool receiveMessage( Stream & stream,
- int & header, int & size );
- }
Spaces after keywords
Spaces are placed between keywords (if, switch, for, return, etc.) and the content that follows, unless it is ;. So you have
- return (x);
.. which contrasts with no space in a function call such as ..
- SomeFunc(x);
Spaces between mathematical operators
Brackets are not followed by spaces, but a single space appears between other mathematical operators.
- int y = (3 + 4 / 2 - 6 + (4 + 2 * array[4]));
Spaces after commas and semicolon separators
- SomeFunc(4, x, 5);
- for(int count = 0; count != 9; count++)
- {
- }
That’s pretty much it. It’s a simple summary, no doubt a more accurate, formal one could be prepared. But that’ll give you the basics
Other aspects of code standardisation such as standard naming conventions are not currently supported by VS. It would be interesting to see an optional scheme where violations of some convention could be flagged as errors.