Accessing the internal calendar database inside Google Android applications
Posted by jimblackler on Oct 23, 2009
The Android phone operating system provides close integration with three excellent services from Google; email, address book and calendar. In addition it has a thriving third party app scene with a great variety of free and commercial applications on the Market. In theory this should mean that apps can provide new services to the user based on the Google service data they have already synced on the phone.
However in the case of calendar data this has proven a bit tricky. Google provide an API to access calendar data via the internet, and this can be used directly from Android apps. Unfortunately this also requires a working data connection, time and battery life to get at the data. In addition it will need the app to prompt for the user’s credentials (user name and password).
All this seems unnecessary when the data you want is right there on the phone already. Since there is an API that any application can use to access the user’s contact (address book) data directly on the phone without going to the internet. It’s called android.provider.Contacts and is documented here. So why doesn’t android.provider.Calender exist?
The answer
The answer is that is does exist – although it is not documented, and it is not included with the standard Google Android SDK. It is a little-known fact that it is possible to download the Android source, force the provider classes to be included by removing the @hide annotation that protects it, and make your own version of the SDK. This can be compiled against apps from which calendar queries can then be made.
This is how I originally built my app Quick Calendar – a ‘lite’ read only version alternative to the built-in calendar application released early 2009. This uses the same data used by the built-in calendar application, already synced onto users’ Android phones. Judging by my inbox it’s been the most popular hobby application I’ve ever put out. I’ve since had a number of inquires from other developers as to how I managed get at the internal calendar data on Android.
Firstly I would say that getting at the data by a custom-build SDK is possible but awkward. For one thing it is a pain keeping up to date with the latest changes and staying in sync with the Android Eclipse plug in.
The good news is you don’t actually need to use the calendar provider SDK classes to get at the data. Android exposes data across applications by using a feed system similar to web-based feeds, and query syntax similar to SQL. As a result, provided your app has the correct user permission (android.permission.READ_CALENDAR) you can query the database from the names, and continue to use standard SDKs such as 1.5 or 1.6. In the absence of specific SDK support for calendars, it’s only slightly less convenient to directly use the provider’s internal URIs (e.g. “content://calendar/calendars”) directly.
Warning
At this point I should point out that there’s a reason why Google haven’t officially exposed the internal calendar APIs. This is probably because they anticipate future changes to the calendar format. Once they’ve published an SDK the formats are to some extent set in stone and they’d like to avoid that. In my experience the formats have been stable since I first discovered the feed. However, don’t be surprised if future firmware changes break any apps that use the feed. In this event you’ll have to update your app and re-upload it to the Market. It’s not that big a worry, certainly not enough to avoid using this great feature – the ability to present users’ calendar data in new ways to them.
Example
I’ve uploaded an example project to http://svn.jimblackler.com/jimblackler/trunk/workspace/AndroidReadCalendarExample. All the calendar reading code is in http://svn.jimblackler.com/jimblackler/trunk/workspace/AndroidReadCalendarExample/src/net/jimblackler/readcalendar/Example.java.
To read the calendar data in your own app firstly add android.permission.READ_CALENDAR under <manifest> in your application’s AndroidManifest.xml.
Please note that you will probably have to use a real phone to test your app in development, because the emulator included with the SDK does not include the Google services (there will simply be no calendar database present to query).
Then get an android.content.ContentResolver and make a query to content://calendar/calendars to enumerate all the available calendars
on the phone. The ‘_id’ column will give you the calendar’s ID (referenced in events). You can get rough documentation of all the columns supported by looking at core/java/android/provider/Calendar.java. (As mentioned previously, this file is part of the public open source Android project but is not part of the official Android SDK from Google)
- ContentResolver contentResolver = context.getContentResolver();
- final Cursor cursor = contentResolver.query(Uri.parse("content://calendar/calendars"),
- (new String[] { "_id", "displayName", "selected" }), null, null, null);
- while (cursor.moveToNext()) {
- final String _id = cursor.getString(0);
- final String displayName = cursor.getString(1);
- final Boolean selected = !cursor.getString(2).equals("0");
- System.out.println("Id: " + _id + " Display Name: " + displayName + " Selected: " + selected);
- }
Once you have a calendar ID you can use your ContentResolver object to obtain the events from that calendar. Note how a ‘where’ clause of ‘Calendars._id=??’ is employed to fetch only events of that particular calendar. This clause could query whichever columns your app required, using an SQL-like syntax. Note also how the Uri.Builder was used to build up a URL including date bounds for the query.
- Uri.Builder builder = Uri.parse("content://calendar/instances/when").buildUpon();
- long now = new Date().getTime();
- ContentUris.appendId(builder, now - DateUtils.WEEK_IN_MILLIS);
- ContentUris.appendId(builder, now + DateUtils.WEEK_IN_MILLIS);
- Cursor eventCursor = contentResolver.query(builder.build(),
- new String[] { "title", "begin", "end", "allDay"}, "Calendars._id=" + id,
- null, "startDay ASC, startMinute ASC");
- while (eventCursor.moveToNext()) {
- final String title = eventCursor.getString(0);
- final Date begin = new Date(eventCursor.getLong(1));
- final Date end = new Date(eventCursor.getLong(2));
- final Boolean allDay = !eventCursor.getString(3).equals("0");
- System.out.println("Title: " + title + " Begin: " + begin + " End: " + end +
- " All Day: " + allDay);
- }
Note that all dates in the calendar format are stored as UTC (the number of milliseconds that have elapsed between midnight 1st January 1970 and the event in Greenwich UK).
This is the basics of calendar access on Android. I haven’t covered all the columns (these can be seen in the SDK source linked above) and I haven’t covered modification. Notheless I hope this information allows other developers to build great calendar-aware apps for Android. Please do leave queries in the comments here, and if you use this information to make an app please do tell us about it in the comments here.
Update
To access the Corporate Calendar on Motorola devices, use “content://calendarEx” in place of “content://calendar”.
Update 2
For Android devices using 2.2 (Froyo) or greater, where previously you had content://calendar you should write content://com.android.calendar
BBC News – a new Widget for Android
Posted by jimblackler on Jul 3, 2009
Update
28th May 2011: BBC News is now UK & World News. Two years on, two million downloads later, same app, new name. I hope you all continue to enjoy reading the BBC News site through my app.
Original article
 BBC News is a widget for Android for that shows you the latest news headlines in a compact 2 x 1 widget on the Android home screen. Clicking on the widget takes you to a full list of headlines and more story details.
BBC News is a widget for Android for that shows you the latest news headlines in a compact 2 x 1 widget on the Android home screen. Clicking on the widget takes you to a full list of headlines and more story details.
In the headline view, clicking on a headline will in turn take you to the mobile version of the BBC News page on your Android browser.
Feed selection
Each widget can be customised to show content from any of the BBC’s feeds. The default is the Most Popular feed, but users can choose others such as Sports headlines, Entertainment or Technology news.
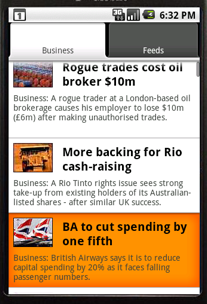
Android users outside the UK will see the international versions of feeds and stories. UK users will see the local version by default, although any user can switch between UK and international versions in the Preferences.
You can have multiple widgets on your home screen. They will not normally show the same story, so if you set up three widgets from the same feed you will have the first, second and third headlines shown, in the order the widgets were added.
This isn’t a general purpose feed reader. It is customised to the style of the excellent BBC News feeds to give the best experience. I saw some RSS widgets but they try to include too much text on the widget, and the result is hard to read. Also they did not use the thumbnails that accompany each story, losing the visual appeal that they add.
Download
Download BBC News from the Android market now.
Credits
This program is free software under the Apache license. Supported by BBC Backstage.
I hope you enjoy BBC News. As always, leave bugs and requests here. Even if you just enjoyed the app and would like to let me know. I read all comments but I have only around an hour a day for development so I usually can’t fulfil requests. I normally act when several people start asking for the same thing.
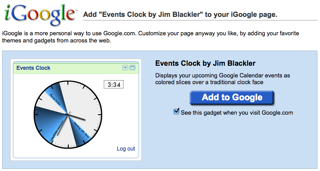
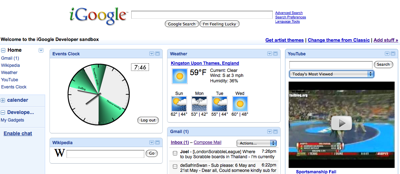
Events Clock: A Google Calendar Visualisation with iGoogle capability. Written in ActionScript (Flash), Java (Google App Engine) and JavaScript
Posted by jimblackler on Apr 26, 2009
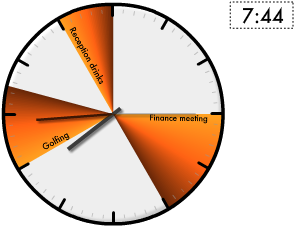
Events Clock is an experimental visualisation for your Google Calendar. It shows your upcoming events as coloured slices around a traditional clock face.
The visualisation shows where the hour hand on the clock will be when each event is in progress. The calendars shhown will match the your existing selection of visible Google Calendars. The colours are taken from the colour you have selected for each Google Calendar, with the exception of events in the past, which are shown in grey.
If there is any doubt as to where the 12 hour period begins and ends, a dotted line is shown. Clicking on the events will send you to the page on google.com/calendar for that event.
Links
To view Events Clock as a stand alone web page, click here. If you don’t use Google Calendar, or don’t have any events in your calendar over the next ten hours or so, click here for a demo.
To add Events Clock as a gadget on your iGoogle page, click here.
Concept
The idea came from the desire to see at a glance what I was supposed to be doing over the course of the day. The original idea was for a mobile phone application. However, once I’d developed a Flash prototype, I discovered iGoogle Gadgets, and the two seemed an ideal fit. I adapted the visual design for the smaller area and it seemed to work well.
As an iGoogle gadget, you’ll see an instant pictorial representation of your day’s events whenever you navigate to your Google homepage.
Accessing Google Calendar data
Events Clock uses a method called AuthSub. This enables it to get access to your Google Calendar data, with no possibility of access to anything else from your Google account. When you click to grant access, a new browser window is opened pointing at a page on Google.com. Here you can allow access to Events Clock. If you have to enter any passwords you are informing Google.com. My site will never see this information. It can’t even see your user name, or email address. All it gets is a token from Google that allows it access to your calendar data. This token is stored, encrypted, as a cookie in your browser.
Note that the Google authorisation screen warns that Events Clock has not been configured for secure access. I have in fact developed secured access, but a possible bug in App Engine appears to be blocking the secure authorisation requests.
App Engine
I used Google’s new cloud computing platform App Engine to host Events Clock. This is possible now that App Engine supports Java. This allows my app to benefit from the scalable, and of course free, hosting. The development went reasonably smoothly, although there were some teething problems with the Google Data access.
Feedback
Events Clock is a concept application, so I’d be very interested to hear your feedback, or reports of technical issues. Please leave comments on here on this blog.
BBC Listings viewer for Android
Posted by jimblackler on Feb 19, 2009

For Android phone owners in the UK, BBC Listings is a viewer and search assistant for the BBC’s TV and Radio schedules.
Users select from a list of channels, then view the schedules for that channel, one day at a time. Clicking on a program shows you a synopsis, and allows you to add a reminder to your Google calendar. Sky+ users can set their Sky+ boxes to record BBC TV programs by a text message.
(This message is prepared by the application and sent from the phone, but requires the phone to be registered for the Remote Record service with Sky. Refer to the Sky website for how to register, and costs and limitations of the Sky+ text message Remote Record service.)

Limitations
Because it gets its data from the BBC’s web services, internet access is required. Currently, one week’s worth of future listings and one week’s worth of past listings are available.
To search the listings press Menu and Search. Results are returned sorted by channel and then by date.
Download
Look for the application in the Android market (requires a UK registered mobile) or download it directly here
License
This application is free software. Supported by backstage.bbc.co.uk
History

0.9.1 : The first published version.
Feedback
If you have any comments or queries about this application, please leave them on this blog.
QuickCalendar, an application for Android written in Java
Posted by jimblackler on Jan 30, 2009
I’ve just released a simple utility QuickCalendar onto the Android Marketplace.
It’s a simple application that displays the current and the next (or the next two) events on the notification bar of your Android phone.
I wrote it because I miss a similar feature from my last phone, a Windows Mobile device. The trickiest part was getting access to the calendar data. There is a provider for calendar data, but unlike the contacts provider it is not part of the standard SDK. However the functionality can be obtained if you get the source (Android is open source), adjust the exported items and build your own SDK.
I may write an article on how to do this if there is demand. Also I will release the source for the application when I have OKed it with my employer. In the meantime you can use the application yourself by going to the Android Marketplace on your phone and searching for QuickCalendar.
Downloading
Get it from the Market, or here
Update
![]()
I’ve had some nice comments and feature requests (always welcome). As a result I’ve fixed some bugs and added some features.
- 0.9.29:
Search button supported on devices that have a hardware search button.
Corporate Calendar supported on Motorola handets.
Widgets refresh immediately when calendar is modified, when preferences are modified, and when the screen is enabled.
Progress indicator for main page.
Widgets to not refresh when screen is off, to save battery.
Refresh rate can be configured in preference screen.
Bug fixed with widget font size. - 0.9.18 : Cupcake version! Gadget for home page available. Colored indicators in task bar. Also: German language support.
- 0.9.17 : Bug fix release (service not starting on phone power up since 0.9.13).
- 0.9.16 : 24hr (aka military time) format not used in category view unless is on in phone preferences.
- 0.9.15 : Bug fix release (preference changes not taking effect).
- 0.9.14 : Context menu selection for time events. Day group headings correct in all time zones.
- 0.9.13 : Now possible to specify any time (up to 999 weeks) to look ahead for notifications and for the main event list. You are not limited to the pre-set durations. New notification icons more in keeping with the Android conventions. New choice of event list format of ‘grouped by day’ or the original classic layout. Events can be shown colored by the calendar color.
- 0.9.12 : Fixed bug introduced in 0.9.11 (time zones didn’t work). Sorry everyone. Daylight savings time should also work properly now though.
- 0.9.11 : Improved progress indicator. Attempted bug fix on calendar preference screen.
- 0.9.10 : Search option – now possible to search calendars! Minor cosmetic improvements.
- 0.9.9 : New icon from Darrel Austin. Another ‘all day’ event fix. Fixed problem with apk size.
- 0.9.8 : All day events sort correctly in all time zones. All day events future day names correct.
- 0.9.7 : Up two four alerts. All day events work in all time zones.
- 0.9.6 : aDogTrack support. Notification icons can be enabled in preferences.
- 0.9.5 : Less obtrusive notify icons. Start service on power on option.
- 0.9.4 : Ability to select/deselect calendars to alert (where you have multiple calendars).
- 0.9.3 : Fixed problem where the notifications stopped updating.
- 0.9.2 : Fixed problem where the time zone was ignored.
- 0.9.1 : The first published version.
Viewing raw XML traffic when using Google Data Java Client APIs
Posted by jimblackler on Oct 23, 2008
The Google Data Java Client APIs provide a convenient way for Java prorgams to interface with Google’s public Data APIs, for Google calendars, contacts, and many other services.
It’s such a good abstraction, however, there is no clear way of seeing the underlying XML of the feed. When debugging, and for their interest, programmers may wish to see this data – it’s supposed to be human-readable after all.
After at least an hour of playing around I found the commands to enable the logging in the client’s initialization. Traffic will then be output to the console at run time.
The gotcha is that enabling verbose output on Java’s logging requires not just the logs to be set to Level.ALL, but also the underlying handlers.
Here’s the code.
- import java.util.logging.Logger;
- import com.google.gdata.client.http.GoogleGDataRequest;
- import com.google.gdata.client.http.HttpGDataRequest;
- Logger.getLogger(Logger.GLOBAL_LOGGER_NAME).getParent().getHandlers()[0].setLevel(Level.ALL);
- Logger.getLogger(GoogleGDataRequest.class.getName()).setLevel(Level.ALL);
- Logger.getLogger(HttpGDataRequest.class.getName()).setLevel(Level.ALL);
Bringing ‘yield return’ from C# to Java
Posted by jimblackler on Oct 12, 2008
Consider a function that collects and returns a list of results. It might look like this:
- public ArrayList<String> retrieveAll(long requesterId);
Or even better, this, so it could use anything that implements Iterable<>:
- public Iterable<String> retrieveAll(long requesterId);
However, storing the results in a container which is then returned may be inefficient for the application. It may be better to enable the calling code to act immediately on each collected result rather than first waiting for all results to be collected and stored. If that were possible..
- No memory would be used to store a list.
- Results could be presented to the user straight away.
- Calling code could abort the collecting process part way through based on its own logic – for instance if it already has more results than it can handle.
Custom iterators
One way to avoid an intermediate list is for the collecting function to construct a custom Iterable<> object, which constructs Iterator<> objects that contain the collecting logic. Each execution of next() calculates the next value and returns it straight away for the calling code.
The difficulty for the programmer is that this may require a significantly different structure of the collecting code. This code has to store any state from result to result as private variables inside the iterator. Call stack is reset with each result, so algorithms that use recursion are not possible.
More convenient for the programmer would be a technique that allows the collecting code to keep control of the machine state during the collecting process.
Yield return
C# has ‘yield return’ which allows a function to be structured exactly as if it is building a list. It may keep its own state in local variables and the call stack, but still present each value to the calling code immediately as it is found.
Java doesn’t have yield return, but another pattern that could be used is this:
- public void retrieveAll(long requesterId, ResultProcessor<String> collector);
Where ResultHandler<> is a simple interface to an object invoked by the collecting code to return individual results as they are collected.
- public interface ResultHandler<T> {
- void handleResult(T value) throws CollectionAbortedException;
- }
It is left up to the calling code what ResultHandler<> implementing object to supply, and how to handle the data. Anonymous classes would be quite neat here. For instance, a caller could output the results to a console like so:
- retreiveAll(myId, new ResultHandler<String>(){
- public void handleResult(String value) {
- System.out.println(value);
- }
- });
The collect() function may abort the collecting operation part way through by throwing a CollectionAbortedException.
The disadvantage to this approach is that it is a little less convenient from the perspective of the calling code. The function has a novel pattern, taking ResultHandler<> as a parameter rather than the more familiar Iterable<> as a return value. Logic has to be embedded inside an anonymous or specially constructed ResultHandler<> class.
Unlike the case of returned Iterables, the calling code can not use ‘for each’ loops on the result. Nor can it store or pass around the Iterable<> to other systems as a parameter.
Solution : The yield adapter
A best-of-both-worlds solution would allow a collecting method based on ResultHandler<> to be automatically adapted at run time to an implementation based on Iterable<>. A data-collecting function implemented in this form (convenient for the collecting code) …
- public void retrieveAll(long requesterId, ResultHandler<String> collector);
.. would be adapted into this form (convenient for the calling code)..
- public Iterable<String> retrieveAll(long requesterId);
This would provide the same benefit C# programs get from yield return. Namely, the ability for both collecting code and calling code to have their own machine state and callstack control throughout the entire collecting and processing operation. It is not necessary for either side to separate logic into methods inside anonymous classes. Collecting code can use complex recursion algorithms. Calling code can store and defer use of the Iterable<> used to collect results, or pass them as parameters to other functions.
| Approach | Collector controls flow | Caller controls flow | Requires list | Caller can abort collect | Uses new thread |
| Collector builds and returns list in form of Iterable<> | yes | yes | yes | no | no |
|
Collector returns Iterable<> containing logic |
no | yes | no | yes | no |
| Caller passes in ResultHandler<> | yes | no | no | yes | no |
| ResultHandler<> wrapped to Iterable<> with yield adapter. | yes | yes | no | yes | yes |
How it works
I am not the first engineer to attempt to bring yield to Java. Aviad Ben Dov’s article in 2007 http://chaoticjava.com/posts/java-yield-return-code-published/ describes a way to do this using bytecode manipulation and classloader modification. My view is that a solution in Java alone would be more practical as a portable library.
My starting premise was that if calling code and collecting code are both to have their own call stack, this could only be achieved with the use of multiple threads.
In addition, I was aware of a Java collection SynchronousQueue which is designed to allow two threads to pass values between each other, each in turn yielding control to the other.
The Yield Adapter simply makes a new custom Iterable<> which is returned to the calling code. The iterable creates iterators on demand, which also starts a new thread for the collection, and makes a SynchronousQueue for communication between the two. Results are wrapped in message object and, .put() into the queue on the collecting side. The iterator side uses .take(). There is also some extra logic to ensure that incomplete reads do not result in leaked resources.
Please note that although the adapter uses threads, the code does not normally need to be ‘thread safe’ in the classic sense. That is because there is never a time that both threads are executing simultaneously. One thread always ‘yields’ to the other. The exception to this is if multiple iterators were ever in effect at once.
Source and demos
The adapter source can be found here with the interfaces employed all here.
A demo here shows how the adapter can be used to allow a recursive scan of files and directories, returning the result through an iterator.
A more complex demo here returns all possible ways the letters in a word can be rearranged, without repeats.
The library source can be downloaded with Subversion or your browser here and the tests and demos are here.
Feedback
I hope that this small library will allow people to develop complex algorithms that present results to calling code as iterators.
If you have any comments on the code, please add them as comments on this article.
Update Feb 2009
Many thanks to Dominic Lachowicz who brought to my attention the fact that the SynchronousQueue does not in fact stop both threads running at the same time. A revision checked in today uses a Semaphore object to achieve the desired behaviour.
Selecting a number of random elements from a list, without repeats. An implementation in Java.
Posted by jimblackler on Apr 13, 2008
A project I’ve been working on required a random selection of postings to be shown to users. The entries were to be drawn from a larger list : a cache of references to posts held in memory.
My first effort at the selection code simply copied the original list, shuffled it, then selected the first ‘n’ entries (where ‘n’ is the number of required postings). A colleague remarked that this was hardly an optimal use of time or memory. So I decided to write a a general-purpose function to select ‘n’ unique entries from a list of ‘m’ entries – using as little memory and processing time as possible.
A naive solution
The most obvious solution to the problem is to repeatedly draw random entries from 0.. n of the list. To reduce the repeats, keep a record of the indices of the random entries already selected. Then, as each new item is selected, the existing list is checked to see if the entry was already taken.
The problem with this is that as more entries are selected the likelihood of such a collision increases. The execution time of the function cannot therefore be predicted. In some cases where the number to select was very large this could make the function quite slow. You could speed it by using different containers and such, but a better approach seems to be avoid collisions in the first place.
Consider a case of selecting five random entries from a list of ten. The first entry index can be found by picking a random number between zero and nine. When making the second selection however there are now only nine remaining unselected entries. So if we pick from zero to eight, then find a way of converting this number (the index of unused entries) into a full source table index, we have avoided the possibility of collision altogether.
The method
My solution calls for items chosen using a random number generated between 0 and m-c where ‘c’ is the number of already selected items. This represents the relative index of unchosen entries, not the actual entries themselves. This number is then converted into the actual entry index by an algorithm.
This algorithm involves iterating backwards through the list of already picked random numbers. The principal is at each iteration to convert the index from 0… m-c space to 0 .. 1+m-c space. In other words the space of the previously selected element. One single operation can do this, and at the same time avoid any potential collision with the last drawn entry in its target space. The operation says “if the already selected entry’s unchosen entry index is the same or less than the current index number then increment this index by one.”
When all already selected entries have been processed in this way, the resulting index is guaranteed to be in 0.. n space and clear of any collisions with already selected entries.
The method has an order of execution n*m / 2, and temporary storage requirements of n indices. This is stable and predictable however so it is a in improvement on collision avoidance methods that would mean repeating random selections.
Code
Here is a ready-to-use implementation in Java.
- import java.util.List;
- import java.util.Random;
- import java.util.ArrayList;
- public class ListUtil {
- /**
- * Create a new list which contains the specified number of elements from the source list, in a
- * random order but without repetitions.
- *
- * @param sourceList the list from which to extract the elements.
- * @param itemsToSelect the number of items to select
- * @param random the random number generator to use
- * @return a new list containg the randomly selected elements
- */
- public static <T> List<T> chooseRandomly(List<T> sourceList, int itemsToSelect, Random random) {
- int sourceSize = sourceList.size();
- // Generate an array representing the element to select from 0... number of available
- // elements after previous elements have been selected.
- int[] selections = new int[itemsToSelect];
- // Simultaneously use the select indices table to generate the new result array
- ArrayList<T> resultArray = new ArrayList<T>();
- for (int count = 0; count < itemsToSelect; count++) {
- // An element from the elements *not yet chosen* is selected
- int selection = random.nextInt(sourceSize - count);
- selections[count] = selection;
- // Store original selection in the original range 0.. number of available elements
- // This selection is converted into actual array space by iterating through the elements
- // already chosen.
- for (int scanIdx = count - 1; scanIdx >= 0; scanIdx--) {
- if (selection >= selections[scanIdx]) {
- selection++;
- }
- }
- // When the first selected element record is reached all selections are in the range
- // 0.. number of available elements, and free of collisions with previous entries.
- // Write the actual array entry to the results
- resultArray.add(sourceList.get(selection));
- }
- return resultArray;
- }
Windows desktop alerts for remote Subversion repositories. A .NET 2.0 application in C#
Posted by jimblackler on Mar 27, 2008
Part of my last job involved some management of a large code base. I wanted to keep an eye on activity on the Subversion source control database. In particular I wanted to know as soon as someone had checked in and what the changes were.
There are many plug-ins available for Subversion (also known as SVN) that will email interested parties when the repository changes, but my experience with these is that they create so many emails that people end up turning them off. Also, they need administrator access to the database which not everyone will have.
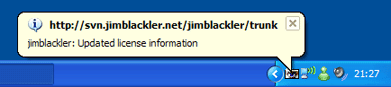
I hit on the idea for a “notifier” application for Subversion that would act like the gmail notifier, letting interested parties know as soon as an SVN database is changed. The Windows balloon alerts are ideal for this sort of thing, so I wrote an application for Windows Forms .NET 2.0 which I am ready to publish today.
SVNWatch
SVNWatch is a Windows application that provides desktop alerts when nominated SVN repositories are changed.
The application runs in the status bar. Alerts when the repositories change take the form of messages in status bar ‘balloons’, and a change in the appearance of the status bar icon.
Clicking on the status bar icon will display a list of the new SVN log entries since the last scan operation.
The application can watch an unlimited number of SVN repositories.
Prerequisites
SVNWatch requires two other components to be present on the user’s PC:
- The .NET Framework version 2. Vista comes with this pre-installed. For XP, this can be downloaded from the Microsoft website here.
- The Subversion Windows client software (“SVN.EXE”). This can be downloaded from the Tigris/Subversion website here.
This is required because SVNWatch invokes the SVN.EXE to interface with the repositories, rather than using an internal static library. I had poor results getting the same results out of the standard API that are available through the SVN.EXE route.
The main dialog
The main dialog lists the watched repositories, provides options to manage the list and gives information about forthcoming scans.
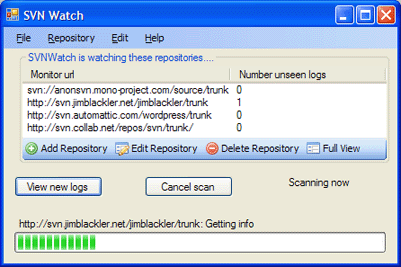
Click on the ‘Add Repository’ toolbar button or from the Repository menu select Add.
A New Repository dialog will be shown. Under Monitor Url enter the URL of the repository, for instance http://svn.jimblackler.com/jimblackler/trunk.
Click OK to add and start monitoring the repository.
First time connection
SVNWatch will fetch and display the first batch of logs. If there is a technical problem connecting to the repository or fetching the logs, this will be displayed in the bottom of the main SVNWatch dialog.
Regular scans
As long as SVNWatch is running, it will regularly scan repositories for new logs
to report. The frequency of scans can be changed in the Settings.
When new logs are available a notification balloon will be shown in the task bar. If just one new log is seen, a quick summary of the check in comments will be shown. If more than one log is available, the number of logs available will be shown.
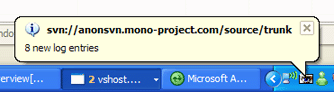
Clicking on the bubble will show a full and detailed list.
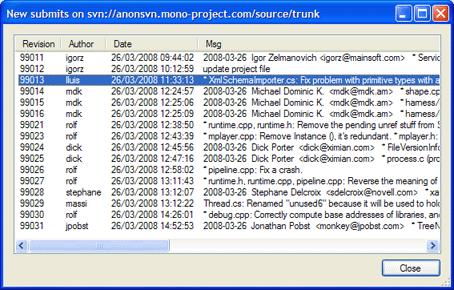
In addition, the task tray icon will change to indicate there are new logs that have not been viewed by the user.
If new logs are available, they can also be viewed by clicking on the View New Logs button.
Edit repository settings
Repository URLs or other settings can be edited at any time by selecting the repository in the main list and selecting Edit Repository.
The user can also view when the last scan was performed and what the outcome was. This can be useful for troubleshooting problems to do with database connection.
The Maximum Fetch value indicates the largest number of logs to download. This is necessary because some long-established SVN repositories are very large.
Settings
Settings, which include the repositories scanned, are automatically saved and retrieved. They are stored for each Windows user.
The settings file can be found in a location such as C:\Documents and Settings\User Name\Application Data\SVNWatch\settings.bin where User Name is the current logged in Windows user name.
The settings can be edited by selecting the Edit menu then the Settings menu item.
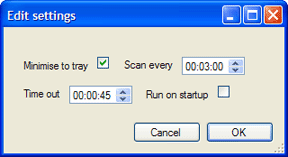
- Minimise to tray
- Scan every
- Time out
- Run on startup
When the application is not in use it is only shown in the system tray, not the taskbar.
The interval in which to scan each SVN repository for changes.
The amount of time to wait for remote operations to complete before giving up.
When checked, the program will start running as soon as the user logs into Windows.
Download
Download SVNWatch as an executable installer from here. Before running SVNWatch, go to the Tigris official Subversion website and download and install the Windows Subversion client (used by SVNWatch).
Alternatively, you may obtain the source code from my own SVN repository here. The project can be built with Visual Studio 2005 C# Express or other later versions of Visual Studio. SVNWatch and its dependent projects are open source, licensed under the LGPL.
Obtaining inline XML C# documentation at runtime using .NET 2.0
Posted by jimblackler on Mar 23, 2008
C# .NET provides a standard mechanism for programmers to inline XML documentation in their programs. Classes, functions, properties and more can be augmented with comments, and the build system creates amalgamated XML files accompanying the program output. A variety of tools such as Sandcastle can build help files from the data. Visual Studio 2005 and 2008 also supports the scheme with keyboard shortcuts and optional build warnings for missing comments.
- /// <summary>
- /// An example C# class
- /// </summary>
- /// <remarks>
- /// This class illustrates how a class can be marked up with inline C# comments
- /// </remarks>
- class SomeExampleClass
- {
- /// <summary>
- /// An example of a property
- /// </summary>
- public int ExampleProperty
- {
- get { return somePrivateVar; }
- }
- }
Unfortunately, many programmers have observed that there’s no way to discover these comments at runtime by reflection. All manner of alternative information can be accessed with reflection – but not the XML comments.
The solution
This documentation can be discovered at run time with a little extra code, as I will demonstrate. The reason the comments can’t be discovered by reflection alone is because they are not included in the .NET assemblies (.EXE or .DLL files), but are conventionally included as .XML files to accompany the assembly files.
I’ve provided a simply class library for .NET 2.0 called DocsByReflection that will when possible return an XmlElement that describes a given type or member. This can be used to easily extract comments at runtime. Here’s an example of how:
- XmlElement documentation = DocsByReflection.XMLFromMember(typeof(SomeExampleClass).GetProperty("ExampleProperty"));
- Console.WriteLine(documentation["summary"].InnerText.Trim());
This would ouput “An example of a property”, extracted from the code comments in the code fragment at the top of the article.
The class works by locating the .XML file accompanying the assembly that defines the type or member (discovered using reflection). Then the .XML file is loaded into an XmlDocument, and the ‘member’ tags are scanned to find the one that refers to the target type or member. This tag is returned as an XmlElement which contains the free form XML that these comments can contain (e.g. including HTML markup).
This method relies on the existence, on disk, of the generated XML. It must have the same name and location as the generated .EXE or .DLL accompanying it – with only the extension changed. This will happen by default when building with Visual Studio, once documentation is enabled (see below). If you are distributing your program and expect the distributed version to discover the comments in run time, you must also distribute the XMLs alongside the executables. This is commonly seen in any case. Note that many of the framework executables (for instance those found in C:\WINDOWS\Microsoft.NET\Framework\v2.0.50727) are accompanied by documentation XML files.
How to use
Download the library source as a zip file here, or use Subversion to update to the very latest version here and here.
(Updated 18/3/08 for bug fix – see comments).
Load the DocsByReflectionDemo.sln to see a simple example of how to use the library. This gathers and prints information about a class type, some functions, a property and a field.
Using in your own code
In Visual Studio, set up your own project that includes XML comments.
(Note that the XML documentation output is not enabled by default in Visual Studio. Go to your project properties, select Build, and under the Output section check the box that says XML Documentation File. It is very important that you do not change the location of the XML file or this method will not be able to locate it at run time.)
If you have not already, add the comments in Visual Studio. By default, pressing forward slash three times when the caret is positioned before the start of an element you wish to document (such as a class or method) will insert a documentation template for you before the start of the file.
Add the DocsByReflection project to your solution and a Reference to it from your project. Add the line “using JimBlackler.DocsByReflection;” to the top of your .CS file. The call se the functions DocsByReflection.XMLFromType() (for classes, structures and other types) and DocsByReflection.XMLFromMember() (for methods, properties and fields) to fetch XmlElement objects that represent the documentation for that type or member.
Query the returned object to read the documentation. For instance, xmlElement[“summary”].InnerText.Trim(). This locates the summary node, and uses the InnerText property of XmlElement to strip out any XML formatting that may be embedded in the comment. Also, Trim() or a regular expression can strip the unwanted whitespace from the comment.
Comments or problems
If you have any comments or problems with the library, please add a reply to this blog post and I will answer them here.